


Last Updated: Apr 23, 2009
Section 1: Pickering's Support for the M7 Group
Section 2: Evidence of Mixture in M7
Section 3: Flaws in Previous Analysis
Section 4: Methodological Sources of Error
Section 5: 'Majority of MSS Method' and Mixture
Section 6: Counterpoint to a high rating for M7
Section 7: How Voting Systems can go Wrong
Pickering's Championing of the M7 Group
The question of mixture by M7 has inadvertantly become a hot
topic, mainly due to the position Pickering has tried to gain for it in
his attempt to defend the 'Majority of Manuscripts' Method.
This question is important on two key levels:
(1) for the establishment of the antiquity and text of the Byzantine (Traditional) text-type, and
(2) for the establishment of a credible methodology for Textual Criticism.
The issues are hot, because Textual Critics have been divided into two basic camps for the past century:
(1)
the defenders of the Westcott-Hort critical text of the 19th century
(essentially the same as the UBS/NA27 text), who ascribe to the 'oldest
= best manuscript' doctrine, and the eclectic 'variant by variant'
approach. This results basically in adopting the Egyptian
('Alexandrian') text, and
(2) the defenders of the Traditional text of the previous 15
centuries (essentially the 'Received'/Byzantine text), who ascribe to
either the 'text used by Christians' doctrine, and/or the 'Majority of
manuscripts=best reading' approach.
(plenty of individuals have taken moderate positions between these extremes as well).
I am going to take W. N. Pickering's 'APPENDIX G' to his online
book, "The Identity of the NT Text' as representative of his basic
position on the Pericope de Adultera:
It can be found here:
http://www.esgm.org/ingles/appendg.h.htm
"The criticisms of (Hodges & Farstad's Majority Text)
have fastened upon the genealogical reconstruction of John
7:53-8:11:..(here) 16 times out of 27, the reading preferred (by HF) is
actually a minority one. In 11 of those, the text is supported by less
than 30% (of extant mss) against the majority on the basis of internal
evidence. Such a procedure sets aside the argument from statistical
probability. (Critics) point out the discrepancy and wonder what went
wrong: can it be that when confronted with reasonably complete
collations the (maj. of mss) theory just won't work?"...
(ibid. pg 1)
Pickering then spends a good five pages arguing for the independance and quality of the M7 text. The reason for this is simple:
M5 (with 280 mss.) represents about 31% of the witnesses.
M6 (with 246 mss.) represents about 27%, and
M7 (with 260 mss.) represents about 29% of mss.
When
M5 and M6 disagree upon the reading, M7 almost always casts the
deciding vote. This is akin to a three-party minority government, in
which at least two parties must agree in order to get legislation
passed or get anything done at all.
The 'Majority of Manuscripts' Method, and the statistical
probability supporting it, depends upon an actual physical majority of
independant manuscript witnesses.
Because of the strong 'text-typing' of the three groups,
(manuscripts are in close agreement within each group), it essentially
comes down to a 'three-vote' system for readings.
Pickering in fact argues that each of the three groups is an
independant line of transmission and carries essentially equal weight,
thus the Majority Text method should be restored, and the text for the
Pericope de Adultera can be established adequately by simply counting
the manuscripts.

Evidence of Mixture in M7
Because of Pickering's attempt to revive the 'Majority of Mss' Method for the Pericope de Adultera, it is important to present the evidence of mixture in M7 in more detail, and explain the ramafications of this for the 'Majority of Mss.' Method and Pickering's thesis.
The first thing we do is narrow the Variation Units down to those which show variations between the groups of interest. In this case, the unique abberations of M1, M2, M3, & M4 can be ignored, since they are clearly not involved in the textual transmission between the groups we want to look at (M5, M6, & M7).
Using this subset of variations, we place the Groups side by side according to their affinity. While we are here, we note the same thing that Von Soden noted: namely that M6 splits up right down the middle (about 90-100 mss on each side) over five special readings which have no involvement in the other two groups (M5 & M7). Following Von Soden, we split M6 up into two basic sub-groups, M6a and M6b. Let us look at these variants first:

(1) I have used the double-headed arrows for these five variation units, to show that the editing process or alterations could have gone in either direction.
There is no way of knowing from individual readings whether M6a descended from M6b or vice versa. For that we need to examine the readings themselves in detail and as a group, and bring forward other independant corroborating evidence.
But this need not concern us now, since it should be obvious from the first chart above that M6b cannot have been directly involved in processes which created M5, M7, & M6a. None of the variants peculiar to M6b were copied or derived from M5 or M7.
(2) It follows that *if* M7
copied from M6, it was from M6a, not directly from M6b. We may now
eliminate M6b from consideration in the question of interdependance and
mixture between M5, M7, & M6a.
(3) The five Variation Units involving M6b can also be eliminated,
since all three Groups of interest, M5, M7, & M6a have the same
reading in these places (they are not 'variants').
Now the relationship between the three texts becomes quite clear:
It is a case of block-copying and mixture by M7 using M5 and M6a as his
palette:
View One: Mixture by M7
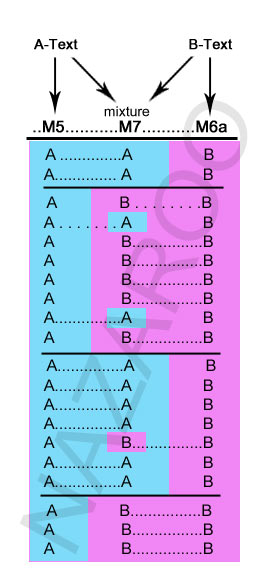
As before, the copyist is rather transparent: He copies the A-Text for the first part, because he is re-inserting or blending the Pericope into the Gospel transmission stream. Two basic possibilities present themselves:
(1) The creator of M7's ancestor was re-inserting the passage into a damaged part of the main textual stream, in which the passage was currently absent, or
(2) M7 was updating the language of an M5 exemplar by comparing and conforming it to the more familiar Lectionary text, as read during church services, creating a 'lectionary' Gospel.
In either case, M7 does what was natural to him, but rather cloddish looking to us: He copies the A-text for a few verses, then follows the B-text for the next quarter, but retains two readings from the A-Text. Here he shows confidence in the paraphrase presented by the B-Text, but nonetheless defers to the authority of the A-Text where he clearly thinks it is important to preserve the exact wording.
For the third quarter, M7's editor falls back upon the A-Text, although in one instance accepts the 'improvement' offered by the B-Text. Finally, M7 follows through to the end using the B-Text, probably, because this famous ending is now likely ingrained in the new form, having been read as a Lection for nearly a thousand years.
The result appears stilted, because this editor only seems to switch between texts when a reading draws his attention to the possibility of a better one, causing him to consult the other text, and continue from there until a new question arises in his mind. But there is nothing really remarkable about this scribe's methodology. The switching back and forth requires no special agenda or motive beyond the attempt to produce the best text out of two equally trusted exemplars. Today he appears naive, but probably did not imagine creating a new 'text-type' from his labours (or a problem for textual critics to solve), only a good readable copy of the story.
The 'block-copying' seems strange to us at first glance, but we must remember that he has switched back and forth at least three times in a mere twelve verses! This editor was not 'lazy' or arbitrary by any means, but rather a diligent and concerned collator of the two basic variant texts available to him in his time. The result is a good, but not that original version of the story in what was for him 'modern language'.
Yet pure 'block-copying' is obviously not really the case: Our editor has consulted both texts throughout the process, adopting readings from one text while copying the other in at least 3 or 4 places. This is the mark of careful comparing by an editor with an agenda, not blind copying.
Further evidence of this scribe/editor's diligence and care are shown in his refusal to introduce ANY significant variants of his own, not found in one or the other of his two sources.
M7 Case Stronger than the M3 Case
One might at first think that our editor's more fuzzy and complex version of 'block-copying', with its exceptions and peculiar patterns due to borrowing, would weaken the case for mixture. But in fact, it turns the case of mixture rock-solid:
Just as fingerprint identification requires a minimal number of unique features to tag a positive i.d., here the unique pattern makes M7's guilt unmistakable. It is the M3 case which has less strength, because only one 'switch' between texts needs to be accounted for, and some other mechanism could be proposed to explain the feature. (see post #22)
Pickering's Version of M7
Now let us consider the alternate possibility, which would be required by Pickering's thesis:
The first thing required to grant M7 independant status, is to rule out mixture by fiat. Since we have denied mixture, we must take M7's text as a valid text in its own right until we can show otherwise.
But now it should be obvious that to account for the facts this way, one or possibly both the other texts must be guilty of the evident mixture:
View 2: M7 okay?
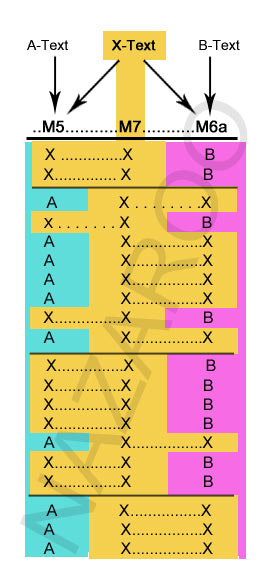
Denying the mixture by M7 hardly erases the phenomenae. Again block-copying and mixture by someone stares us in the face.
In fact, we must now invent at least THREE text-types for our editors to draw from.
We can't assume that our new editors each only had the same two texts,
say an 'X-Text' and an 'AB-Text' available: For no manuscript exists
which has the right A/B variants that M5 and M6a would need to draw
from. So three texts it is: A, B, and X.
But three texts cannot explain the motivations of the new editors, any more than two text sources could. One editor still possesses guilty knowledge of the other's actions, yet inexplicably chooses to use the same sources in the opposite manner, choosing 'left' when his rival chooses 'right'.
The only option is a bizarre conspiracy to ...what? obscure the genealogical relationships of the lines of transmission? Isn't that a little sophisticated for Medieval scribes?
Yes. It would involve advanced abstract mathematical thinking unimaginable until at least World War II.
Asking for the Impossible
What Pickering wants is three independant Groups: M5, M6, and M7. But the phenomenae simply don't allow it.
They can only be 'independant' so long as we don't examine their
actual readings at all! Once we peek inside them, its all over.
This is akin to the 'probability' of a coin toss: As long as we don't look, or actually film the coin flying in the air, we can only give head or tails equal possibilities. But the minute we actually observe the toss, we can see the coin following the laws of Newtonian mechanics in quite a deterministic fashion. We can even predict the outcome before the coin lands.
We can only fit the correlations at hand to a few basic types of process: And NONE of the scenarios allow the three text-types to be 'equal' in weight.
Even if we are undecided about WHICH process actually occured, we know that the three groups cannot be equally accurate.
Lack of Unique Readings Rules out 'Equality'
The only scenario that would allow all three groups to be equal (and therefore equally corrupt!), would be if we discovered that M5 & M6 shared about the same number of readings that exclude M7 as the number of readings that M7 & M5 share against M6, and M7 & M6 versus M5.
But we already know that the necessary corollary is simply false: M7 has no unique readings at all. This damns M7 far more decisively than any other fact, contrary to Pickering. This is the true import of M7's lack of unique readings.
The Third Option...
The only other process that could explain the lack of unique readings for M7 (other than mixture) is a linear editing process:
View Three: Linear Sequence
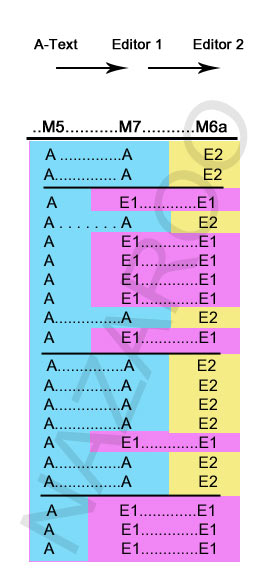
M5 is edited into M7, which is in turn edited into M6 (or vice versa), preventing any unique readings for M7, because all edits are carefully adopted by the next editor.
The two-step process requires two editors. This is more plausible than having M7 at the head of the stemma, but even here we have to account for some peculiar facts:
Why does the 2nd editor adopt all of the 1st editor's readings? If he doesn't know about the 1st editor, why does he only edit the areas the 1st editor has neglected? If he does know about the 1st editor, why doesn't he restore the original text? This scenario requires both editors to be on the same team, and to possess an agenda at odds with preserving the text! But in that case, why do the job in two stages? Why would the 1st editor only edit the text part-time?
But even this process is too clever by half: Whether or not the 2nd editor knew of the 1st, something is amiss.
But regardless, AGAIN M7 loses credibility in this process, being the middle-man in sequence, and having secondary status irrespective of the direction of the process! That is, we would be forced to acknowledge the superiority of either the M5 or the M6 text, but M7 would hold a perpetual 2nd place, with half of its readings known to be wrong.
What possible reason can we have for giving M7 equal 'voting power' for readings when we know half of them are wrong, and we even know which? The Majority of MSS Method is not only redundant here, but results in an error-ridden text.
The problem is, the actual readings place M7 firmly in the middle, from which it can only be superior or (usually) inferior, but never equal. And the one scenario in which M7 could be given at least equal weight demands we give it PRIORITY, destroying the value of Pickering's argument for using any kind of 'Majority of MSS' Method.
If we could be sure that M7 was the ancestor of M5 and M6, then its readings would overrule both of them, even when they agreed against M7.
Flaws in Pickering's Analysis
Eliminating Too Many Possibilities
How does Pickering go so fatally astray? He begins by making unwarranted assumptions from various incidental facts:
"M7 & M5 each stand alone against the rest of the stemma - a condemning circumstance." (appendix G, pg 169)
Wrong. When two parties disagree, one or the other can be wrong, or even both, but they can't both be right. So far so good: Yet the disagreements actually mentioned here do not condemn both parties: merely one or the other. Like Solomon, in the cast of conflicting evidence we have to appeal to other independant methods.
"M5 and M6 never agree...- they are extremes (which makes it unlikely
that either one stands closest to the autograph)." (pg 169)
Wrong
again. It makes it impossible that BOTH can be closest to the
autograph, but one or the other could easily be closest to the
autograph.
The Admitted Mixture of M3 & others
Pickering admits the following:
"...So M5 & M6 are the extremes and M7 & h (M1234) are candidates for mixed texts..."
So Pickering knows of the very real possibility that M7 is a mixed text, (as Von Soden and others have repeatedly said), yet he then later attempts to argue the reverse!
"...A careful scrutiny of h (M1,M2,M3,M4) makes clear that it is a mixed text, drawing from M5 and M6."
When it is of no relevance to the 'Majority of MSS' Method, Pickering is quite capable of identifying mixture! Yet even here he undermines his own position, and accumulates evidence against M7's independance and priority:
If M5 and M6 were actually used as sources for h (M1 to M4), then they are obviously very old, perhaps the oldest texts extant!. Having established that they have already been used once as sources by a mixer, they are a priori the best candidates for the head of the other stemmatic section for M7.
As for the likelihood of mixture, Pickering freely concedes the general practice, based upon the copious and blatant evidence:
"Considering
the fluctuating alignments throughout the variant sets it would appear
that copyists frequently had access to more than one exemplar and were
not above picking and choosing -- it seems reasonable to suppose they
would be most willing to do so when confronted with confusion in the
tradition." (pg 175)
But in fact here Pickering is conceding far too much. We have a thousand manuscripts, and evidence of only about seven 'editors', and only two of them were 'mixers'. That's less than one out of a hundred copyists willing to mess with the text. the other 990 scribes took no liberties, and reproduced the texts they were given pretty much exactly as they were supposed to!
The Strange Construal of the Evidence
Yet he proceeds to ignore this evidence when dealing with M7. Rather, M5 and M6 are grouped together and devalued:
"...Since M6 has 7 singular readings and M5 has 5, it is clear that
each has corrupted its exemplar and neither can stand closest to the
Autograph."
This simply does not follow at all. 'Singular' readings are not a mark of corruption when the readings are readings of large groups (300 mss), and not lone manuscripts! The meaning and import of 'singular' here is completely different for Groups than for individual manuscripts. While this usage of the word 'singular' may be legitimate, its significance is context-dependant and precision is critically important here.
Yet Pickering claims to be aware of the difference between Groups and individual manuscripts, because he makes this complaint against others when discussing genealogy:
"Robinson-Pierpont
continue to misunderstand what Hodges-Farstad and I mean by 'stemma'.
We are not talking about genealogy or descent of (individual) MSS; we
are talking about the genealogy or descent of readings.
Von Soden's groups are based on 'profiles' of readings in common, a
concept that R-P seem to accept, a concept that seems to me to be
obviously valid, and necessary. I think we all would agree that
'genealogy' as applied to individual MSS is unworkable."
Here Pickering unwittingly erodes his own
position. He admits genealogical relations are currently 'unworkable'
for individual manuscripts. So far so good:
But then he acknowledges genealogy IS workable for groups and/or well
defined text-types. Yet if so, the necessity for the Majority of MSS
Method now becomes questionable. Advocates had used the impossibility
of genealogical work as one powerful justification for the Majority
Method.
The Logical Fallacy of Rejecting Genealogical Methods
But it is enough that Pickering has admitted the value of genealogical methods in the case at hand. For genealogical methods allow us to establish original readings WITHOUT resorting to simple manuscript counting, and have the potential to actually over-rule the evidence of a 'majority' reading.
If we assume as an axiom that all mss and groups are 'equal', and equally corrupt, then even 'singular' readings of whole groups (one group of seven is a minority) would indeed carry a probability of being false.
But we cannot afford to make such a methodological error. Not only do we doubt that all 'Groups' are equal, we have positive evidence that they are NOT. Pickering has no hesitation admitting this in regard to Groups M1 through M4:
"Groups
M1,2,3,4 are frequently internally divided, and their constituentMSS
often go astray with a variety of added variants which are not recorded
on following chart..." (pg 165)
In the footnote on the same page, Pickering amazingly concedes the following:
"But see ch 7...where I argue that demonstrated MSS Groupings and relationships supercede the mere counting of MSS." (pg 165)
Pickering seems quite willing to set aside 'Majority Readings' where the evidence warrants it!
The assumption that all manuscripts and/or groups are equal would be an actual necessity if we had no access at all to the manuscripts and their readings. Then laws or reasonable presumptions concerning 'probability' would be our only guide.
But in the case of the Byzantine/Majority Text, we actually have what Pickering and others claim to be extremely good and representative samples of the texts as they were transmitted.
Here we might as well get busy establishing the groupings and reconstructing the relationships between text-types. If we can't do that, it would imply that we DON'T have a thoroughly representative sample of the main textual stream of transmission.
Misinterpretation of Evidence
"M7 gives no evidence of being mixed. It has no singular readings." (pg 171)
This to me betrays a complete miscomprehension of the evidence before us, and also of the implications of key types of evidence, when it does exist:
(1) M7 definitely gives undisputable evidence of being INVOLVED in a process of mixture. The fact that it is the 'monkey in the middle' actually makes it a prime suspect in the mixture as well. Pickering's mis-statement borders upon actual deception.
(2) M7 has no singular readings (of significance). But Pickering's understanding of the significance of this fact is completely upside-down. Sources for mixture can expected to have singular readings, since they are only partially used by the mixer to create the mixed text. The mixer on the other hand, has no need or motive to invent NEW readings. He already presumably has plenty of readings in his exemplars to choose from.
The Strange Favouritism and Exemption of M7
Later, Pickering discusses the two basic possibilities:
When discussing h ( M1...M4 ), Pickering has no problem suggesting mixture:
"Since h has obvious secondary readings, including two conflations,
plus a deal of mixture, [mixture] seem to be the required
interpretation." (pg 171)
Whether or not there are actual cases of 'conflation' is a secondary point.
Conflation is not a necessary feature of mixture, nor even good evidence of it.
Hort's eight examples hardly stood up to
critique: why is Pickering even trying out a 'tool' he himself
previously spurned? In contrast to his chapter on John 8:1-11,
Pickering's Appendix D on Conflation is spectacular: there he provides
extensive evidence that 'conflation' is largely conjectural, if not
imaginary. It can be found online here:
http://www.esgm.org/ingles/appendd.h.htm
The second point is significant: Pickering acknowledges the presence of mixture-like phenomenae as evidence of actual mixture. Why doesn't the same situation work for M7?
But when he discusses the exact same problem for M7, instead we get this:
"If M7 is viewed as a mixture of M5 and M6 the even selection is
strange, plus a total lack of conflations. The six splits in M6 plus
the fact that M6 has seven singular readings and M5 has five, while [M7
has none] points to [making the common ancestor M7] as the best
interpretation."
Why is the 'even' selection strange? The mixture would have to be reasonably 'even' to be convincing at all. A couple of possible readings from one source with the vast majority of readings coming from the other would barely stand up to labelling as 'mixture'.
Of course in some sense the behaviour of M7 and its relationship to M5 and M6 IS strange: strange enough to clearly convict M7 of 'block-copying'!
Again 'lack of conflations'? Since when have conflations suddenly become an important criteria of mixture? Most Textual Critics defending the Majority Method rejected 'conflation' as improbable a century ago.
And again Pickering completely misunderstands or misrepresents the meaning of the lack of singular readings in M7.
Mixing is by definition a non-creative type of act. If the editor had the talent or felt he had the mandate to 'add' novel readings of his own, why bother to depend upon sources at all?
What Caused Pickering's Blind-Spot?
Pickering is so intent upon re-enthroning the Majority of Manuscripts
Method, that he actually paints himself into a ridiculous corner. He
proves too much: by trying to gain equality for M7 he actually
undermines the whole enterprise and the credibility of simple
manuscript-counts.
Trying to win 'equality' for the middle-text in a blatant case of
mixture not only creates an implausible case, it creates a case that
begs the reader to reject the OTHER texts as secondary. The Majority of
MSS Method is the loser in this exchange either way.
Perhaps not so surprisingly, after 4 pages of strained attempts to
legitimize the text of M7 (pgs 170-175), Pickering virtually throws his
hands in the air and declares:
"I
confess that I find discussions of probabilities to be wearisome and
frustrating. [!!] It is seldom possible to rise above mere
speculation." (pg 176)
Why does does Pickering feel this way? Apparently his case isn't convincing, even to himself.
Let us put our finger on the problem: Pickering is ably equipped to cut through the hype of the followers of Hort, and marshall the analytical skills to demolish the last 100 years of 'textual criticism'.
But when it comes to developing a rational and solid methodology for textual criticism himself, he is still in the process, and has been unable to deliver the goods. He cannot be blamed for this lack: after all he has spent most of his text-critical career critiqueing Westcott & Hort and their successors. One cannot be expected to do everything.
Perhaps after being steeped in the audacious fraud of Hort for so long (and its horrendous results), Pickering has been virtually turned off of any genealogical methodology for all time. It is hard to blame him, if he has become too jaded to ever give honest genealogical investigation a try. He has become a seasoned soldier in the battle for the bible.
But this would be a tragedy. Perhaps Pickering, after due
consideration, may come to realise that genealogical methods are indeed
possible, and positive results can be had.
It seems that a misunderstanding concerning the meaning of some of the evidence, plus more concern for ideology than for scientific disinterest caused Pickering to waste some effort in a misguided and ineffective defence of the Majority of MSS Method.
Summary of the M7 fiasco
(1) What is Desirable for the Majority of MSS Method?
Pickering begins by observing that three groups, M5, M6 & M7 each contain 250-300 manuscripts. These Groups distinguish themselves both in stability and definition of their texts as well as numerical abundance. The three Groups together represent over 80% of all the existing manuscripts of John that contain the Pericope.
The other four groups taken together only represent about 13% of available manuscripts, and each of these Groups (M1,M2,M3,M4) are often internally divided and inconsistent in their texts.
In any version of a 'Majority of MSS' Method, these four Groups (M1-M4, which Pickering designates with the letter 'h') would be virtually ignored. Even were they all to agree on some reading, their collective voting power would be overwhelmed by any one of the other Groups (M5-M7).
On the other hand, suppose even one of the big three Groups were disqualified: Then, if the other two split on a reading, the 'h' cluster (M1-M4) would hold the precarious deciding vote, and it too would likely be split.
The result would be that many 'majority' readings would in fact have won with a minority of votes: about 250-300 versus 120 or less, with a whopping 250-300 manuscripts abstaining (or disqualified). These 'reading elections' would be awfully close, even ambiguous, with some of the worst manuscripts holding the deciding vote.
This is wholly unappealing if not intolerable to anyone putting their faith in the 'Majority of MSS' Methodology. The only way to avoid any possible ambiguity is always include the three main Groups, M5, M6 & M7, and have them swamp the readings from the minority cluster h (M1-M4).
The larger body of 'good' manuscripts rather conveniently divides
itself into THREE Groups, preventing any troublesome ties in a 'Group
Vote', and the voting blocks are always an unambiguous majority of
about 500-600 manuscripts, even with only 2 out of 3 Groups supporting
a reading.
Potential Snag 1:
Yet there are already cracks in the armour of this happy picture: Von
Soden noted that M6 itself is really about evenly split down the
middle, forming TWO Groups of about 100 manuscripts each on its own
(M6a & M6b). Thus the potential for more ambiguous votes is there,
especially if fresh collations or new manuscripts upset the balance.
Potential Snag 2:
More worrisome than this however, is the possibility that a large Group of manuscripts like M7 might be found guilty of 'mixture'. Why does this matter? Because its secondary status would seem to require introducing a 'weighted' voting scheme.
In a 'weighted' scheme, the Groups are no longer 'equal', and individual manuscripts are no longer equally credible, but rather rated or even eliminated based upon the quality of their witness. In our case, if M7 was found to be a later, secondary text, its testimony must have less weight than either that of M5 and M6, 'tie-breaking' when M5 and M6 split would be problematic to say the least.
Thus Pickering and the Majority of MSS Method supporters would like to see M7 given equal status with M5 and M6, and have them all treated like independant 'lines of transmission' of equal importance.
(2) The M7 'Problem': Mixture
The M7 problem is contained in two critically important pieces of evidence revealed by the variants:
(1) M7 shows no independance at all. It has no unique readings which are not already found in M5 and M6.
Yet if the three Groups were truly independant lines of equal age and extent, we would expect they would all have developed some significant and unique readings.
Pickering's Explanation
Taken alone, this might be explained away, as Pickering attempts to do by the following substitute explanation:
a) According to Pickering, the 'singular' readings of M5 and M6 mean that they are actually inferior to M7, and have both suffered corruption. Therefore placing M7 at the head of this sub-stemma is the 'best interpretation'.
b) According to Pickering, the fact that M5 and M6 never agree together against M7 means that they are 'extreme' texts, far from the original source. By corollary, M7 is closer to the original source.
c) According to Pickering, the lack of unique readings of M7 are a sign of 'purity' of its text, and the care of its copyists.
d) According to Pickering,'mixed texts' should have unique readings. M7's lack of unique readings means it 'shows no sign of mixture'.
e) According to Pickering, 'mixed texts' will typically have 'conflation'. M7 has no apparent examples of conflation, so again, it lacks the characteristics of 'mixture'.
f) According to Pickering, if M7 is viewed as a mixture of M5 and M6, 'the even selection is strange'. Presumably, he refers to the 'block-copying' features, or else the fact that M7 uses each source in about equal amounts.
g) According to Pickering, 'mixture' was free and common, common enough to apparently account for TWO mixed texts (M5 & M6), not just one (M7).
h) Pickering also presents a few pages examining individual
variants and naturally extolling the M7 reading in each case. This also
gives apparent support to M7's independance and priority.
Pickering makes as good a case as can probably be made. And if there were no analysis, criticism and opposing facts, many might be convinced that Pickering has got it right. But lets take a second look: (next section)
Counterpoint to Pickering's Argument
a)
By 'singular' readings, we are talking about large well defined Groups
of 250-300 mss (=text-types), not individual manuscripts.
Pickering
wants to portray M5 and M6 as late text-types arriving at the end of a
long line of 'normal' transmission, and suffering from accumulated
(unguided) 'corruption'.
But this is not the picture presented by the actual facts at all:
Actually, if this truly were a 'normal' process for all three Groups,
and the variants were 'accidental' or at least unguided and randomly
accumulated errors, we would expect TWO features from the extant mss:
(1) The 'errors' would have a spotty "shot-pattern", randomly distributed across the text in both M5 and M6.
(2) The 'errors' would have widely varying attestation within the Groups, being introduced at different times in the copying process, with older changes supported by older representatives and newer changes being minority readings.
This is exactly the OPPOSITE of the actual state of affairs. :
(1) If we take M7 as a base, the 'errors' in both M5 & M6 form clear 'block' patterns, showing a systematic and deliberate intent, not 'accidental' or unguided accumulation.
(2) The text-type attestation is crystal-clear and virtually homogenous in both M5 and M6, meaning there was no long process of corruption at all, but a SINGLE deliberate edition by at least one of them.
(3) If M7 is taken as the base, the 'block-copying' pattern is an identical but complete 'negative' or mirror image between the two Groups. This is 'fantastic' if not impossible, without an intimate connection between them, and no known motive can be conjured for these plainly deliberate 'mirror-twin' editions.
So Pickering's attempt to paint the three Groups as 'independant lines of transmission' with corruption for some, securing equality or better for M7 is wholly discredited by the actual variants. At best, its a game of musical chairs, and some Groups are going to be left with an awful reputation, and no plausible right to equal voting status.
b) the 'Extreme Texts' argument by itself cannot disqualify BOTH extreme texts. It can only disqualify one of them.
The whole premise of a normal line of transmission, with a one-way process gradually corrupting the text by accumulating errors (accidental or deliberate) virtually requires that the source and the final (latest) text be the two most extreme points in the process.
Pickering's own arguments from statistical probability come into force here:
It is not merely that the Majority Readings are spread throughout the expanding fan of copies, and that this text will be statistically closest to the original, but that this original text will naturally be one of the extremes in a set of multiple extreme texts.
Only a case of multiple independant and radically different PROCESSES which produce differently natured texts can produce more than two extreme texts.
Only the existance of three or more extreme texts have the potential to leave the original text 'in the middle' by some qualitative measure or scale. And this measure would have to be based upon two or more distinguishable processes that specifically account for the qualitative measure employed.
c) the lack of unique readings of M7 are NOT an unambiguous sign of 'purity' of its text, or the care of its copyists.
Another childishly simple explanation is equally possible: That M7 was a recent 'edition' created by mixture, which then gained popularity for a brief period.
Its lack of unique readings very likely only
means that M7 is just a very LATE text, without a long history of
transmission in which to accumulate any unique errors.
The fact that the best explanation so far for M7's text is that it
is a mixture of M5 and M6a underlines the fact that it probably comes
much later on the timeline than M5 or M6.
d) A lack of 'singular' readings is no indication of a lack of mixture.
If anything, the opposite is the case. We fully expect that an editor in the late Medieval period, at a time when the relative accuracy of competing versions was unknown, would attempt to construct the 'best' text by comparison and blending. Since his purpose would be in restoring the original text as best as possible, it would be against his own interests and philosophy to deliberately introduce new and novel readings of his own. No such creativity is expected.
And this is precisely what M7 displays: a single editor, mixing two earlier texts (M5 & M7) rather arbitrarily but with a deliberate pattern and purpose, without adding anything of his own to the traditions he inherited.
e) Conflation is neither a necessary feature of mixture, nor is it even expected to be found.
Conflation, strictly speaking, is where a scribe, rather than choosing between two alternate variants, combines them, preserving both. The result is a longer 'mixed' text of a special kind: a bloated ,'Conflated', and often redundant or confusing text.
But conflation is largely a 'theory', meant to explain some peculiar variants generally in the Synoptics (where there are parallel accounts that might suggest harmonization or conflation to a scribe), particularly in the Western text-type, which is perceived to be 'longer'.
John is a 'singular' Gospel in the first place. There are no real 'parallels' to compare and conflate, and no real sources of multiple readings that would lend themselves to 'conflation' in the Johannine variants.
Even among the unusually large number of variants collated for John 8:1-11, there are very few variation Units which present the necessary features for a possible 'conflation', and Pickering knows this.
To get an idea of just how rare even potential cases of 'conflation' are, it should be remembered that Hort (the great salesman for 'conflation') was only able to produce 8 examples out of the entire New Testament! (and of these, half lacked convincing features.)
To expect to even find an example of 'conflation' in a span of a mere 12 verses of John borders on the improbable to hopeless end of the scale.
This would be like trying to detect minute variations in the force of Gravity by juggling bowling balls by hand, or attempting to prove General Relativity by measuring the bending of light with a toy kaleidoscope.
f) The actual choice of the 'mixture' by M7 is not really strange at all, unless we make unreasonable assumptions about the intelligence of the editor.
We have seen that the behaviour of M7 is quite plausible for someone with two equally esteemed texts before him, and a job of creating a 'best' text by intuition. He does nothing that we would not expect a Medieval editor or scribe to do.
It IS strange in the sense of there being an interesting pattern. But this can hardly be stranger than having TWO independant editors producing Mirror-Patterns of each other's editing, if we deny M7 is the mixer.
It is not strange that the editor averages about the same amount of borrowing from each source, since he apparently has no access to knowledge of their true relative value.
Pickering never really shows us why M7 as mixer' is particularly strange. When he does deal with individual variants, its always from the point of view that M7 has the best text. We never get to see his 'evidence' for another view being problematic at all.
g) Mixture was not 'free and easy' as described by Pickering. Finding two other texts guilty of the most amazing and peculiar kind of 'mixture' ever seen, in order to avoid convicting another text is wholly artificial and unconvincing.
Only one other Group can be clearly convicted of 'mixture': M3. One (or two) out of at least six editors or groups is hardly a case of mixture running amok.
If mixture was truly a 'common practice', we would expect no clearly defined and stable Groups. Even (or especially) the larger Groups would be full of the experiments of individual 'free-range scribes', and the text-types would dissolve into clusters of probable readings.
The fact is, the majority of scribes for all the Groups took their copying so seriously and were so accurate that 300 at a time could fix a text virtually down to the word for twelve consecutive verses. This is hardly the evidence of 'caprice'.
The 'fathers' (original editors) of each Group may indeed be characterized by their habits, but that would be less than seven men.
One man borrowed three verses from M5 (the editor of M3), and the only other 'mixer' we can find is the editor of M7!
Where are all the mixers? are they to be found in the handful (less than a hundred) manuscripts that represent 'h' (the M1-M4 Group)? And if we DO discover some wild and crazy scribes there, how are we to relate those exceptions to the 900 editors and copyists responsible for M5, M6, and M7?
Finding both M5 and M6 (two editors/600 copyists) guilty of a bizarre and inexplicable stunt of 'double-inverse' mixture seems unjustified by the actual evidence, especially when the point is just to throw a smoke-screen over M7's plain guilt.
h) There is no case in Pickering's variant-by-variant defence of M7, when HALF of M7's readings may be simply copied from M5, and the other half from M6.
We can't use the readings that M7 shares with M5 to argue that M7 is a
'pure' text. It proves too much. If M7 is pure here, then obviously M5
is too.
To put a case for the priority of M7 over M5, Pickering
must appeal only to those readings it inevitably shares with M6a (a
mere hundred manuscripts). If these together presented a strong and
convincing argument, we might look twice at M5 in those places. But
what then about the betrayal of M7 by M6a almost half the time? What
kind of witness can M6a then be?
Similarly, to make a case for M7 over M6a, Pickering must use
readings shared with M5. But if M5 is a good witness in those cases, it
must simultaneously weaken the case for M7 where M5 and M7 differ.
Its a problem of putting the cart before the horse, and begging
the question. Pickering needs to re-cast his work into two separate
arguments. But in any case, each separate argument would oppose the
other, and it would be hard to believe both were true, even if they
looked convincing!
How can M5 be a witness against M6a for M7, and vise versa, and why should they both only be believed when they support M7?
The only way we could always favour M7 in contests of roughly equal numbers of manuscripts, would be if we had already decided a priori on the basis of other evidence that M7 was vastly superior to both M5 and M6.
The M7 problem is contained in two critically important pieces of evidence revealed by the variants:
(1) M7 shows no independance at all. It has no unique readings which are not already found in M5 and M6.
(2) M7 shows a clear pattern of 'block-copying' and mixture. The best interpretation is that M7 is the guilty party.
Number (2) is the part of the problem that Pickering completely ignores, or else inadvertantly obscures. After studying the manuscript evidence, and the work of generations of other scholars, he can hardly be ignorant of the question and the evidence of mixture by M7.
The fact that he apparently ignores this evidence entirely suggests another agenda: that of defending the Majority of MSS Method, and restoring the text of John 8:1-11 to that found in the majority of manuscripts.
But the response to this is plain, and also the ramafications for the Majority Method.
M7 IS guilty of mixture, and M7's votes must be qualified because the age and reliability of its text is in serious doubt.
The Majority of MSS Method is also in serious question here, because it is obvious that the Pericope de Adultera is the ACID TEST for it.
We will discuss the Majority of MSS Method next.
When Good Voting Systems go Bad...
Lets take a look at Pickering's version of the M5-M7-M6a chart again:
M5 = 280+ mss, M7 = 260 mss, and M6 = 240 mss (M6a = 75 mss) respectively.
But what seems on the surface a 'fair' voting strategy just reproduces M7.
Wherever 2 out of 3 Groups (at 100-300 mss each) agree, we are just going to get the M7 text (although the vote might be rather close if we disallow M6b and/or recollate some of the 800 mss involved.)
This is a similar situation to the case that other Textual Critics have complained about regarding the Majority of MSS Method and its results in the context of the Alexandrian 'text-type' (or at least the Uncials and Papyrii): The Byzantine ('Majority') text always out-votes all the ancient and interesting evidence. It never gets heard, and might as well not vote. Majority rules.
But now the Majority of MSS Method shows that actually, the MAJORITY of manuscripts have become redundant! We can see that we need not have counted all the manuscripts at all. We could have produced the exact same text by burning ALL the other manuscripts and Groups, and simply using M7.
This is far more 'iffy' than chucking a handful of Egyptian papyrii in the garbage (where they were originally found).
The 'Grouping' patterns discovered by Von Soden show that the 'election' has been rigged all along, and only one outcome was possible from the method chosen.
All the other manuscripts might as well not even have been collated. These voters are automatically disenfranchised by M7.
All the other two Groups have been used for, was to 'rubber-stamp' M7. They were never really used or consulted beyond this, nor was their existance or their peculiar readings even explained. But surely a proper job demands this.
In a truly 'fair' or random 'election', we would have expected M5 and M6 voting against M7 once in a while. Thus the 'true text' should have been found at least in part in every major branch of transmission. But here we are told that M5 and M6 have failed to save anything for us. Yet if they are truly secondary, why give them equal voting power at all? Why not just dismiss them as corrupt and redundant, and count votes from M7 manuscripts alone? That is surely what the defenders of the Byzantine/Majority text would do with the Alexandrian witnesses if they threatened to tip the election!
Yet the 'Majority' text turns out to be in a MINORITY of manuscripts. (240 out of 900+, or less than 25%!) This is incredibly suspicious, because had the 'transmission stream' been 'normal' in any rational sense, the data should be entirely different!
Instead of finding the 'true' text in a tiny, closely knit 'Walled City' of pure Trojans surrounded by the entire Greek Army, we should have found the true readings spread randomly and about equally throughout the Mediterranean manuscript landscape.
It's not that it would be 'impossible' that a small number of manuscripts should have a surprisingly pure text: this itself could be the accidental result of a lucky line of 'pure copying'.
But how could a rigidly pure original text exist in almost a third of the manuscripts? Where is Pickering's 'Argument from Probability' for THIS phenomenon? Of course there should be a small handful of manuscripts out of the bunch which are only a few copies away from the original, and have a surprisingly pure text. And naturally, this handful of manuscripts should form a tightly knit Group with relatively fewer variants. But it should be equally true that WITHIN this 'Group', the variants ought to be randomly distributed accidental errors. The actual manuscripts should show independance among their own variants. The TRUE prediction from the statistical model says that this Group should be quite small, or variable in size, depending upon the percent of agreement we choose for a 'cut-off' for inclusion in the Group. But a third of extant manuscripts? combined with an almost complete cookie-cutter pattern of agreement among the manuscripts within the group? There is no such Probabilistic model!
And what about the corrollary?
How could over two thirds of the manuscripts in the transmission have a text which is corrupt in the MAJORITY of variants?
The whole premise of the argument
for statistical probability behind the Majority of MSS Method says this
is darn near impossible! We should be able to get a 95%+ pure version
of the original text from just about *any* random but fairly
representative sample of the 'normal' transmission stream.
And once we abandon 'normal' transmission for either M7 or the rest (it matters not which), how can any single (simple) probabilistic model cover the total transmission picture?
But that is what is required if Pickering and others want to argue for the Majority of MSS Methods on the basis of 'statistical probability'.
The data at the least requires TWO transmission models: one for M7, and one for the others.
And once we admit this, we simply can't have a single, simple voting system. We have to have at least TWO election processes. One for transmission process A, and the other for process B.
These are just a few of the 'problems' with the Majority of MSS Method as it is imagined in its application to the actual Byzantine manuscripts.
We are witnessing the crashing and burning of a NAIVE application of the Majority of MSS Method. The phenomena demand that one way or another, we devalue some of the manuscripts.
Pickering tries to save the 'pure' Majority method, but ends up having to abandon nearly two thirds of the textual stream of transmission as corrupt (M5 + M6 = nearly 600 mss!), and not corrupt in a small way: each has HALF the variants WRONG. They have preserved only 50% of the original readings.
And in order to do this, he must interpret the phenomenae in a way opposite to their natural import. Instead of one 'normal' mixer (M7) we have to look at two perverse 'mirror-mixers' (M5 & M6).
But what if we interpret the phenomenae in the most natural way? Now we have TWO texts: made for two different purposes. The original 'A-text' (M5), and the Lectionary 'B-text' (M6). We have a ready-made and historically plausible explanation for the two texts.
Then we have a late Medieval 'mixer', (M7), who creates a popular text by either updating the A-text (M5) or back-correcting the Lectionary text (M6), and who adds no 'innovations' of his own. His text is popular, and his methods and motives are completely understandable and transparent.
Now we can see we need to apply the 'Majority of MSS' Method with some care and quality control:
We have two different texts, so we have two different 'elections'. Just
as voters cannot vote in elections where they don't reside, so
likewise, manuscripts cannot be counted where they apply either.
We disqualify texts and manuscripts that show plain evidence
of 'mixture' and/or relative 'lateness'. We LOOK at all the evidence,
but in the end we choose the most plausible texts and manuscripts and
readings to reconstruct the original text. We do this by reconstructing
the textual history of transmission in a way that plausibly fits the
known history of the period and the practices, attitudes and motives of
the active participants.