


Quentin's 'Rule of Iron' is in fact really best viewed as a practical way of organizing the data and the probable relationship between three manuscripts or groups. To quote Colwell,
"At the other extreme lies Dom Quentin's rigorous effort to make the genealogical method 100% objective. He argued that community in error is not enough to establish genealogy. Therefore he set forth what he called the Rule of Iron,...
The method is to take the list of variant readings in a particular book or passage as one datum. Then to take up the manuscripts in turn in groups of three until all possible groups of three have been employed...."
(Studies in the Methodology of the Textual Criticism of the NT,pg 77f)
Colwell's brief treatment which then follows hardly explains the technique or its strength. In fact he presents a rather muddled critique that actually supports the value of the method. But then because the method appears to have little value for organizing individual manuscripts today (since most come from independant lines of transmssion), Colwell dismisses it and retreats, siding with Metzger's negative view.
Yet Quentin's Rule of Iron is actually ideally suited to the situation of the approximately seven groups (text-types) representing the Pericope de Adultera. Although a genealogical tree for the actual NT mss cannot be constructed, because so many manuscripts are missing, this is not true at all of the clearly identifiable text-types behind these manuscripts in this case. On the one hand the groups are few enough to make the application practical, and plentiful enough to make the method useful as a tool.
So lets have a second look:
Suppose we have three texts, A, B, and C. We then find the following:
A agrees with B against C: 3 times
B agrees with C against A: 0 times
C agrees with A against B: 2 times!
A, B, C additionally share : 3 readings.
Two possibilities appear obvious:
The 'Zero line' is the key idea here, indicating no obvious dependancy in either direction between B and C. Yet absolute 'zero' is not itself really necessary. We could have a small number of 'false positives' if we are accidentally counting 'agreements' which really reach back to a common archtype or the original text, but that have been lost from some groups. All we really need is a significantly low number for one pair, relative to the 'agreements in error' between the other two pairings.
But now the key point:
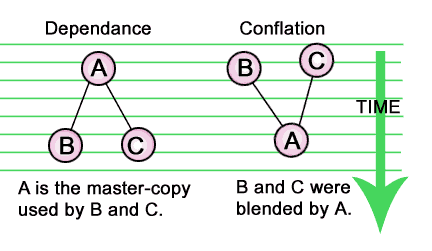
If we were to buy the (now long discredited) view of scribal habits held in the 19th century, we might argue with Hort that 'conflation' or blending is the more likely case, and that A is the later 'harmonized' product. (i.e., that scribes were more likely to conflate or harmonize than omit texts creating diversity).
Nowadays most critics face up to the fact that early scribes appear far more prone to omit words, whether by accident or design, than to incorporate scribal glosses. But this is not a strict truth, only a probabilistic tendency.
Another, even weightier argument in favour of the first model, Dependance (A is the master, and B & C are divergent copies) is this: Ultimately the second model requires yet more hypothetical entities for which we may have no evidence at all:
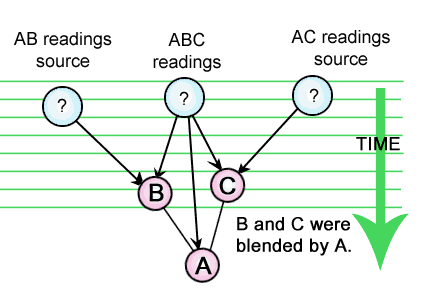
Over half the entities in the new diagram, are wholly hypothetical, although required to provide new independant sources for the 'blending/conflation' view. Unless there is some other corroborating evidence for their existance, we must dismiss the 'conflationary model' as needlessly complicated and artificial.
Finally, even if we accept the 'conflation/blending' view, we have to concede that it must be placed 'late' in any genealogical tree, so that there is something further up to draw from for mixing. So from a practical matter, the first view is preferred on the plain scientific basis of Occam's razor.
We don't needlessly multiply entities or complexities.
Yet the real power and beauty of Quentin's Rule of Iron technique, is that we don't have to choose at all! Once we focus on Affinity rather than prematurely attempting to decide the direction of possible dependance and hence flow of transmission, we only need consider the relative orientation between triplet groups.
Once we have constructed the larger relationship pattern between the groups of triplets, we can then rotate the cluster as a whole, and consider various models of the flow of transmission independantly of the arrangement of the cluster, just as we did with the other method (agreement in error).

Lets see just how handy this approach is:
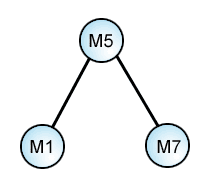
First Threesome: M1-M5-M7
M1-M5 .....: 3 readings
M1 ......M7: 0 readings!
......M5-M7: 3 readings
M1-M5-M7 : 3 readings
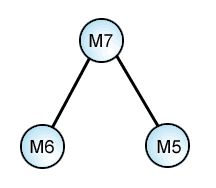
2nd Threesome: M5-M6-M7
M5-M6.....: (1 pt. reading)
M5.......M7: 3 readings
......M6-M7: 2 readings
M5-M6-M7: 1 reading
Now clearly M5 must have descended from M7 or vise versa: but we need not establish which is the case at this point. We only need invert one tree relative to the other and join the overlap. When we have joined together appropriately all our 'mini-trees' we can orient the cluster any way we wish:
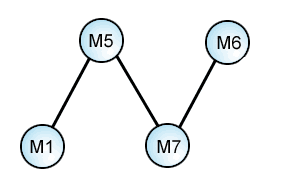
At this point the perceptive reader may ask:
"Wait a minute Nazaroo: wouldn't proceeding in this manner simply create a zig-zag or daisy-chain? Isn't this an arbitrary way of constructing a genealogical tree?"
And you would be correct.
Quentin's Rule of Iron cannot by itself construct an actual genealogical tree. And it is easy to see how a novice might create various arbitrary trees this way. But this is to misunderstand the real value of the Rule of Iron.
What we have here is not a genealogical tree, nor even an 'Affinity' diagram. We have said nothing about distances in the 'diagram space', or relative position of key groups. What the Rule of Iron can offer is backbone, not shape. It is a TOPOLOGICAL tool, not a tool of 'measure', in the parlance of mathematical terminology.
As such, it comes into its own in conjunction with yet other methods and techniques. For instance, in the diagram above, one may immediately ask,
"But surely someone has blended or conflated two sources: was it M5, or M7?"
Surprisingly, there is yet a third option: A two-stage sequential process:
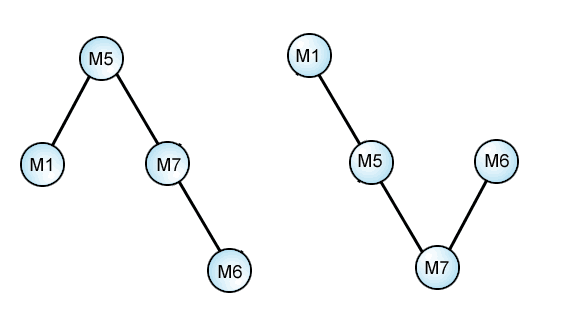
Here we have simply straightened out one leg of the diagram, to give the idea. In any triplet, the two least-related texts are the two extremes. Either could be the result of a two-step process starting at one extreme, and moving to the other. (in the example above, either diagram could also be inverted.)
The Rule of Iron can't decide these issues for us, but there are other simple tests which can.
Strictly speaking, this isn't a 'method' but rather a set of observations.
"But if the individual variation units are independant, how can the order in which they appear have any meaning? Isn't the order of the variants dictated by the text from which they are taken?"
Ah, but the key here is this: It is not the 'order' of the variants per se, but rather the fact that there is, or is not, a pattern in the variations of a certain kind.
"How can that be? The existance of a pattern? In what possible sense could you mean?"
As paradoxical as it sounds, there can be certain kinds of information that can only be stored in the actual pattern of a group of readings, not the readings themselves. One of these pieces of information is who exactly copied who! That's right: Let's see how this could be:
Suppose we want to ask whether or not M7 blended M5 and M6, or instead, M5 and M6 descended from M7. First we take the subset of variants relevant to these three groups.
To add more precision and detail to the analysis, we will also after observing the variants conclude that we can subdivide M6 into two sub-groups, M6a and M6b.
After this, it becomes apparent that if M7 copied from M6, it was from M6a, not M6b, which has peculiar readings not shared by any other group.
We label the text at one extreme the 'A' text, and that of the other the 'B' text. This will become very handy. Now we chart the changes across the groups from one extreme to the other:
...M5..........M7..........M6a..........M6b...
...A............A.............B...............B....
...A............A.............B...............B
...A........... A*............A...............B*
...A............B.............B...............B
...A............A.............B...............B
...A............B.............B...............B
...A............B.............B...............B
...A............B.............B...............B
...A............B.............B...............B
...A............A.............B...............B
...A........... A*............A...............B*
...A............B.............B...............B
...A........... A*............A...............B*
...A............A.............B...............B
...A............A.............B...............B
...A............A.............B...............B
...A............A.............B...............B
...A........... A*............A...............B*
...A............B.............B...............B
...A............A.............B...............B
...A............A.............B...............B
...A........... A*............A...............B*
...A............B.............B...............B
...A............B.............B...............B
...A............B.............B...............B
What we are witnessing here is extraordinary:
First the preliminaries: The five variations between M6a and M6b are isolated individual variants, presenting no special pattern. They are 'bidirectional', meaning either text could have copied and edited the other, and nothing here indicates which.
The other variants are not so ambigous however: M7 follows A (M5) for three verses, then inserts a reading from B (M6a). By the sixth variant he abandons A, and follows B for four variants in a row! Now he is unhappy again and reverts to the A-text for almost the rest of the show, only inserting a B-text reading twice. Finally, he switches back to the B-text again for the last verses.
How do we know this? Here are the alternatives:
(1) Suppose that M5 and M6a copied M7: Then each must have chose to depart from it only in the places where the other DID NOT. Well, not only would they have to know exactly what the other was doing, but the purpose and its result would be preposterous. One of them would have to carefully and intimately know what the other had done, and also be a madman, apparently acting in pure spite of the other copyist.
(2) Suppose a sequence with two editors: either M5--> M7--> M6a, or M6a--> M7--> M5. In this case, we would have to account for TWO "block-editors". Again, collusion and knowledge would be required, but worse, why if say, M6a knew what M7 had done, wouldn't he just reverse the changes, rather than change the portions he knew were good and further corrupt the text?
Only one scenario could account for such a strange process a proposed in (2): M7 might have 'updated' the language of M5, but only in sections, and then M6a simply completed the process. This could account for the appearance of TWO block editors - except for one thing! The actual variants don't support the idea of a 'language update' or some other simple agenda. They are mostly additions and omissions, and don't conform even to a 'tendency' for one or the other!
The simplest and best explanation is that M7 is guilty of 'mixture'.
This only requires one idiosyncratic 'editor'. And in this case, a partial explanation at least is rather obvious: The A-text is the non-Lectionary text, retaining the features of a continuous narrative. M7 knows it is original, and so copies it at the beginning, making the text properly join the previous verses. However, M7 favours the Lectionary text as the more familiar one, (it being read publicly), and prefers its form for the first half of the story. He reverts to the A-text for the rest, but still consults the Lectionary text occasionally.
This enables us to orient our partial stemma the right way up:
Now, just like the chicken-egg dilemma, we can apply our discovery to the complimentary problem of the M5 sub-stemma. While initially the transmission stream could have flowed in either direction between M5 and M7, knowing that it must have flowed from M5 to M7 solves half the problem.
Another way of putting this is that the line joining the two (M5 & M7) can only have one arrow-head.
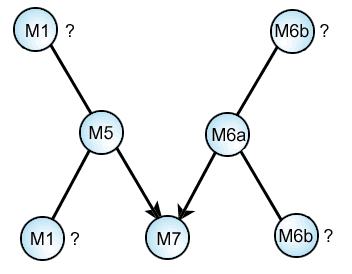
Finally, we want to settle the issue of M1 and M6b. Given the fact that M5 and M6a have already been established as probable sources for a large group of manuscripts with a mixed text, their probable origin is early. Thus without other evidence, the likelihood goes to the precedence of M5 and M6a over M1 and M6b.
By the way, this trick is equally valuable when opposite results are obtained:
For instance, after analyzing the M5 sub-stemma, NO COPYING PATTERN is found, other than the obvious one already discovered in M7. The simple conclusion is that M5 has no evidence of mixture, at least of this kind. This is additional evidence in favour of making M5 the source for M1 also.
Third Threesome: M4-M6-M7
M4-M6 ......: 3 readings
M4 .......M7: 0 readings!
.......M6-M7: 2 readings
M4-M6-M7 : 1 reading
A good solid 'zero-line' gives a vote for M6 at the top of the sub-tree.
Fourth Threesome: M3-M4-M6
M3-M4 .....: 2 readings
M3 .......M6: (1 pt.reading)
.......M4-M6: 3 readings
M3-M4-M6 : 2 (or 3) readings
Here the 'almost zero-line' would seem to put M4 above M3, but we already have reason to suspect M6 as a source of mixture in other sub-trees. Here again we will want to investigate for signs of mixture like block-copying by M4 from M3 and M6.
Fifth Threesome: M3-M6-M7
M3-M6........ : . ( 1 pt. reading)
M3.........M7 : 0 readings!
.......M6-M7 : 2 readings
M3-M6-M7 : 1 reading
Here is the clinching piece of this sub-puzzle. M3 appears below M6 and so we can accept a reversal of the stemma for the fourth Threesome above:
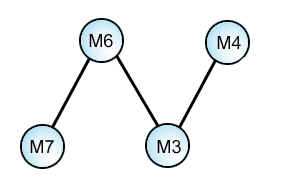
Again however, we are not commited to M4 as a source of mixture, unless we discover some independant evidence. We might also have a case of a multi-step process ending in M4:
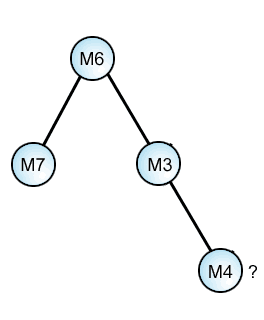
This in fact is likely the case. The M4 witnesses, although significant in size, are all late manuscripts, and we must always keep these aspects of the textual evidence in the background.
Additional and interesting sub-triplets fill out the picture:
(6) Threesome: M1-M3-M4
M1-M3........ : 0 readings*
M1 ........M4 : 0 readings*
........M3-M4 : 2 readings
M1-M3-M4 .: 1 reading
With TWO 'zero-lines' we really have none at all. The data here simply tells us that M1 has no special relation to M3-M4 at all. And this is what we would expect from two texts at opposite ends of a process.
(7) Threesome: M2-M3-M4
M2-M3........: 1 reading
M2.........M4: 1 reading
.......M3-M4 : 2 readings
M2-M3-M4 : 3 readings
Here again no 'zero-line', but rather evidence that is more simply interpreted as a cumulative and linear (sequential) process.
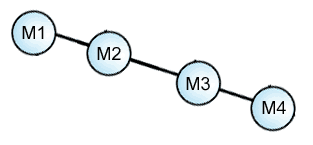
The only clear 'zero-line' in the entire M1-M2-M3-M4 cluster is the following:
(8) Threesome: M1-M2-M3
M1-M2........: 1 reading
M1........M3 : 0 readings!
......M2-M3 : 1 reading
M1-M2-M3 : 1 reading
This suggests M1 is a secondary branch, and the low number of manuscripts combined with its quirkiness confirm it is a dead end that died quickly. (This is Codex Bezae & related mss).
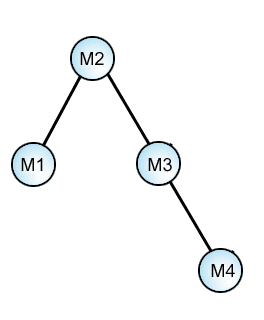
Nor is there any clear relation between M1-M2, and M5:
(9) Threesome: M1-M2-M5
M1-M2...... : 3 readings
M1........M5: 1 reading
......M2-M5 : 1 reading
M1-M2-M5 : 1 reading
Only M1-M2 are closely coupled.
Finally, we get two more nice clean 'zero-lines':
(10) Threesome: M2-M5-M7
M2-M5.......: 1 reading
M2....... M7 : 0 readings!
......M5-M7 : 3 readings
M2-M5-M7 : 1 reading
placing M5 at the head again, and
(11) Threesome: M1-M6-M7
M1-M6......: (1 pt reading)
M1....... M7 : 0 readings!
......M6-M7 : 2 readings
M1-M6-M7 : 1 reading
This reinforces the relative priority for M6 once again.
Combining the data with our knowledge of the number and approximate ages of the mss, gives:
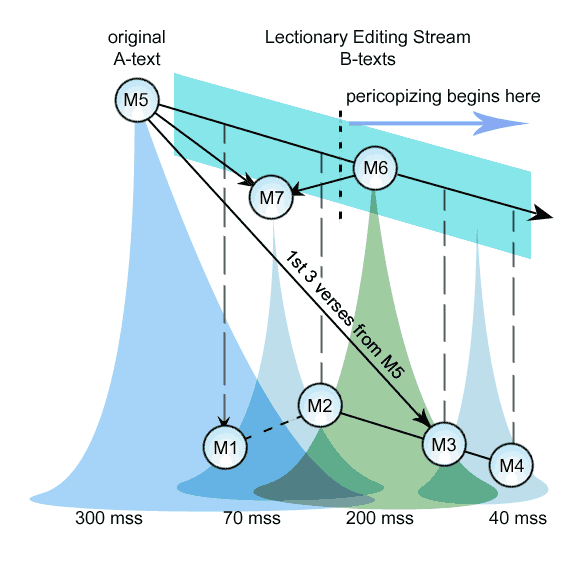
Another powerful organizational tool to give the data some meaningful structure is the Extreme text-type approach.
Here, after comparing the various groups, we seek out the two least similar texts. These become the extreme ends of an unknown process, which we then try to analyse. It is a basic scientific 'black box' technique, whereby we try to assess the hidden structures and processes that gave rise to the two (or more) extreme texts.
In our case this is very straightforward: The two most extreme texts are the M5 text (which we will label the A-text), and the M4 text (which we label the B-text). We separate the texts themselves from the actual groups representing them, since these may only be imperfect images of an underlying source-text or process.
Next, we eliminate idiosyncratic variants from our master-list, which don't relate to the two extreme texts. These we would label 'AB' readings, (and their variants) cases in which BOTH extreme texts had the same reading, but some other witness strayed on its own. (a good sign that the reading is spurious and relatively unimportant to the main process).
The new subset of variants will give us a remarkably clear picture of the interaction and interprenetration of the two competing texts. This is done by organizing the groups of manuscripts in columns, placing the nearest neighbour texts right next to each other.
It is important to note that these closely related texts are organised on more than just their raw 'affinity' as we have understood it in previous methods:
Here the closeness is measured not only in the simple 'count' of variants, or even their order, but in the actual variants themselves that are shared. This gives an extra dimension of accuracy to the ordering of the groups, and their possible interdependancies.
The columns actually form a 'toroid' or vertical cylinder that can be formed by overlapping the left and right edges of the chart. This allows one to view both texts simultaneously as they compete, and watch the 'border skirmishs' between them in the form of 'mixed' texts and possible shared sources.
The B-text:
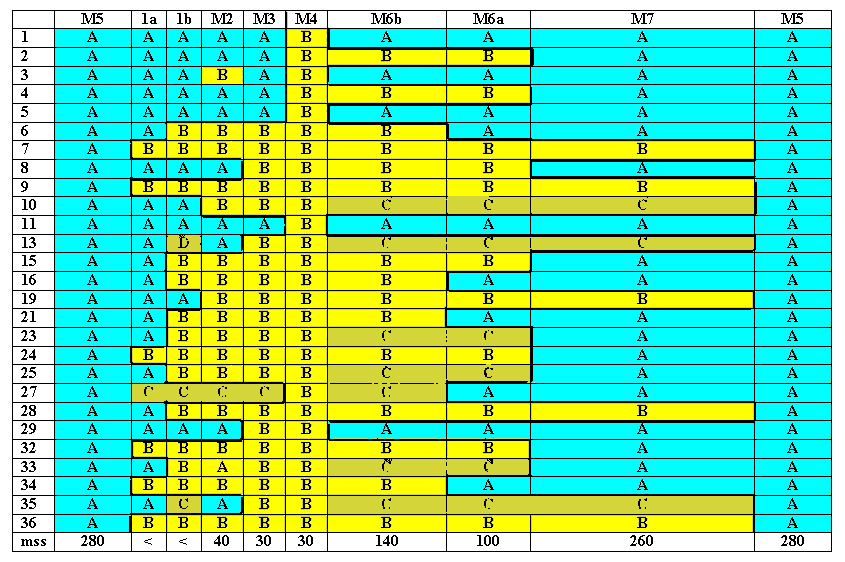
The 'C' and 'D' readings are simply peculiarities not found in the two extreme texts. On the other hand, we already know that the M4 text is a small closely interdependant group of late manuscripts, reflecting the most advanced and extreme 'Lectionary' style text. (M4 is actually Family 13, which we have discussed elsewhere).
It may be that some 'C' readings are more likely to be the 'true' Lectionary text, if by that we mean the early-finalized and dominant Lectionary text. Thus the 'C' readings of variant units 10, 13, 27 and 35 are probably Lectionary readings, and the quirks of Family 13 are late accretions which had no opportunity to penetrate the main Lectionary transmission stream.
So by organizing the data in this way, we can make some tentative corrections to our raw classification of the variants. This gives us a better view of what really went on in the copying and editing process.
What we see in the 'mixed' texts of the skirmishing borders are partly attempts at re-inserting the Pericope back into defective manuscripts from the Lectionary tradition, with varying success, and little standardization in the handling.
We have used column width here to give a suggestion of the actual number of manuscripts for each group. But the M5 and M7 groups have been toned down to allow more detail for the other columns. In actual fact, the A-text is overwhelming in its numerical superiority. Here is the same basic chart placing the A-text in the center:
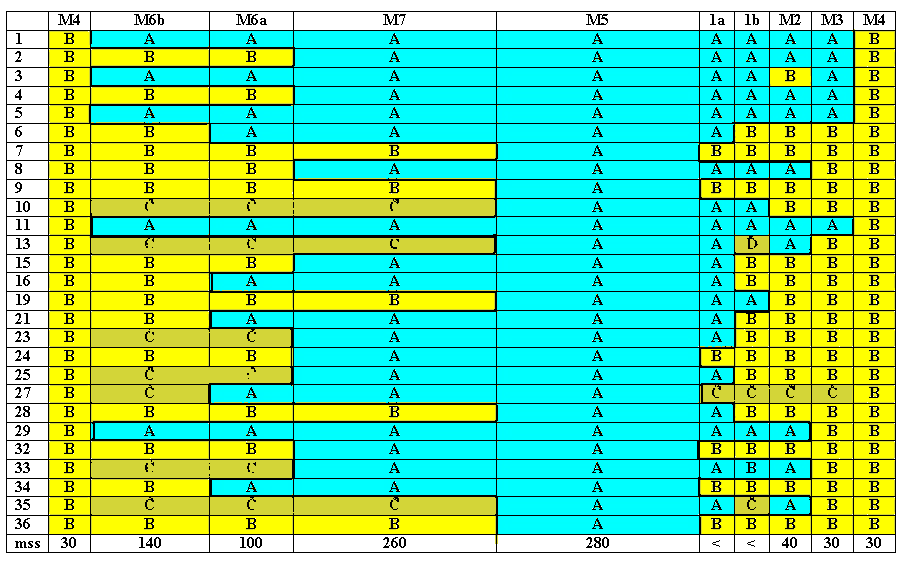
At this point, we may as well be frank with the reader: Its pretty much all over now but the shouting.
Although we don't have to commit to any particular version as though it were written in stone, it would take alot of strong internal and external counter-evidence to tip M5 off of the top of the Genealogical Stemma.
Although we can continue to analyze both groups, individual variants, and the editing and transmission process, all we are going to learn from that is more about the Lectionary history than the original text. We pretty much have that in hand already.
The Text of the Pericope de Adultera is now fairly set, although there are about five interesting variants that call us to their attention:
____________________________________________
και επορευθησαν εκαστος εις τον οικον αυτου
Ιησους δε επορευθη εις το ορος των ελαιων
ορθρου δε παλιν παρεγενετο εις το ιερον
και πας ο λαος ηρχετο (+προς αυτον B1)
και καθισας εδιδασκεν αυτους
αγουσιν δε οι γραμματεις και οι φαρισαιοι προς αυτον
γυναικα εν μοιχεια καταληφθεισαν ( /κατειλημμενην B1)
και στησαντες αυτην εν μεσω
λεγουσιν αυτω πειραζοντες (-πειραζοντες B1)
διδασκαλε αυτη η γυνη κατεληφθη επ' αυτοφωρω μοιχευομενη
εν δε τω νομω Μωσης ημιν ενετειλατο τας τοιαυτας λιθοβολεισθαι. συ ουν τι λεγεις?
τουτο δε ελεγον πειραζοντες αυτον ινα εχωσι κατηγορειν αυτου.
ο δε Ιησους κατω κυψας τω δακτυλω κατεγραφεν εις την γην μη προσποιυμενος.
ως δε επεμενον ερωτωντες αυτον ανεκυψας ειπεν προς αυτους
ο αναμαρτητος υμων πρωτος επ αυτην τον λιθον βαλετω.
και παλιν κατω κυψας εγραφεν εις την γην.
οι δε ακουσαντες εξηρχοντο εις καθ' εις
αρξαμενοι απο των πρεσβυτερων (+εως των εσχατων B2)
και κατελειφθη μονος ο Ιησους και η γυνη εν μεσω ουσα.
ανακυψας δε ο Ιησους, και μηδενα θεασαμενος πλην της γυναικος, ειπεν αυτη,
που εισιν εικενοι, οι κατηγοροι σου ? ουδεις σε κατεκρινεν ?
η δε ειπεν,
ουδεις κυριε.
ειπεν δε ο Ιησους,
ουδε εγω σε κρινω. (/κατακρινω B1)
πορευου και μηκετι αμαρτανε.
____________________________________________
The 'B1, B2' in this case means the editors of the 'B-text', or Lectionary text.
(see further discussion).
The most interesting variant is the attempt to finalize the incident and have Jesus instantly forgive the woman, and so bring the story to an end and allow the passage to stand alone as a public reading on various saint's days.
But the original intent, and tougher but deeper reading is 'judge' not 'condemn'. As a blatant typology of Israel, the Messiah sends Israel away with a warning, and postpones the entire trial to give time for more reflection. This is lost in the Lectionary version, but could hardly have been invented by scribes, or even ecclesiastical authorities.
I am providing a rough translation of the passage here for English speakers, so that anyone can follow along, and see what the results of reconstruction produce, as well as the significance of the variants:
'...and each went to their own home,
but Jesus went to the Mount of Olives:
and at dawn again He came into the temple. (1)
and all the people were arriving, (2)
and being seated He was teaching them.
But the scribes and Pharisees bring to Him a woman
having been found in an adultery,(3)
and standing her in the midst, they pressed Him saying,
"Teacher: this very woman was taken in the act - committing adultery! (4)
But in the Torah Moses commanded to us
that such be stoned (to death).
You then, what do you say?"
This they said provoking Him,
that they might have something to accuse Him of.
But Jesus, having leaned down, was writing in the earth, taking no notice of them. (5)
And as they continued harrassing Him, rising, He said to them,
"Let the sinless one among you be the first upon her, to cast the stone!" (6)
And having again leaned down, He was writing in the earth.
But those, having understood, and by conscience being convicted,
were exiting one by one, beginning from the eldest. (7)
And Jesus was found alone, and the woman standing in the midst.
But Jesus, rising, and regarding no one but the woman, said to her ,
"Where are those - your accusers?
Did no one condemn you?"
And she said,
"No one, Lord!"
And Jesus said,
"Neither do I judge you:
Continue on, and cease from sin." (8)
1. (cf. Zeph 3:4,5 Judges 19:24-27)
2. (B1, TR reads: 'coming to Him')
3. (John's narrative is deliberately ambiguous, cf. Matt.7:1)
4.(Pharisees use verb-form implying guilt:contrast with 3.)
5.(proper rendering of μη προσποιουμενος)
6. (M5 preserves Semitic word order cf. Deut. 17:7 Heb)
7. (B1, TR adds 'unto the last', = misreading of αρχαμενοι)
8. (B1, TR adds ' κατα-' making 'judge' read 'condemn' )
Let's take another look at our preliminary stemma:
Obviously its a bit unsatisfactory on a number of points, the main one being an actual time-scale.
One of the key points to keep in mind while looking at the chart is that the 'text' or 'text-type' is not at all the same as the actual group of manuscripts that it is represented by. First of all, obviously, the 'text-type' is an averaged text.
But more importantly, in our case, most of the 'text-types' represented here are many centuries older than the manuscripts. This is just the nature of the case when the bulk of the manuscripts from the earlier periods are simply missing, either lost, worn out, or destroyed.
What we need to do is clearly separate the base-text or source for each group of manuscripts from the group itself, and place each of those entities on a real timeline with realistic and plausible dates.
And in examining this data (the age of the manuscripts themselves) against the internal evidence and historical data, we can see why earlier investigators have been led astray occasionally.
For instance, Codex D (Bezae) is one of the oldest manuscripts to present evidence, certainly a 'text' for the Pericope de Adultera. However, we saw from collating the variants that this text is in fact secondary to the M2 group. Yet the M2 group, although containing an ancient array of manuscripts, technically holds a later position on the timeline.
M2 has manuscripts like S (with asterisks), U, Lambda, miniscule 28 and 700. For all their antiquity, they seem to lose against the pedigree of D, checking in at least as early as the 5th, possibly even late 4th century.
This forces us to postulate much earlier archtypes for both groups, which are only represented by relatively late manuscripts. In this way, we can account for the secondary nature of M1, and at the same time explain the assigned dates of the extant witnesses.
Here's a look at an improved version of our stemma:
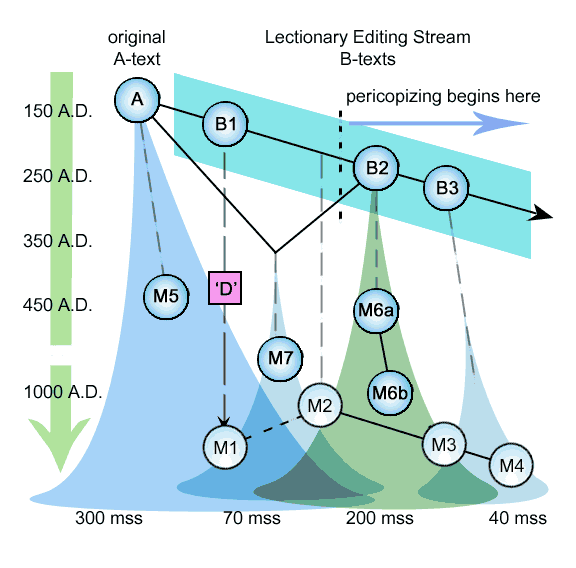
We have now fully separated the sources and the underlying editing process from the extant groups.
We can sketch a timetable and a brief outline as follows:
(1) By about 150 A.D. at least, after the battle with Marcion, the normal Gospel text of John was stabilized and contained the pericope.
(2) At around the same time, the Lectionary system was well into the first stages of its development, mainly in the form of 'church copies' of the Gospels edited and segmented for public reading. This included a phase of excising the passage (at least in Egypt) to minimize fights with Alexandrian Jews and scribes in the critical early stages of evangelization. The state of the Lectionary text is well represented by such papyrii as P66 and P75. (for John).
(3) Between 180-300 A.D. the Gospels were translated into other key languages, such as Latin, Aramaic (Syriac), Ethiopic. These translations were mainly based upon the Lectionary style texts since the priorities and most pressing needs were copies intended for underground church services. This was the most efficient way to service the largest populations with the fewest copies. (These were hand-made and expensive). Naturally such translations dropped the controversial verses and picked up other peculiarities known to have originated in Lectionary editing process. The Old Latin and Old Syriac copies would reflect some of these alterations to the Gospel text.
(4) Around 350 A.D. Eusebius under Emperor Constantine attempted a revision, but mostly produced a 'Lectionary' style text to be adopted by the large congregations and churches. 50 'Great Bibles' were produced, clearly based upon the older Lectionary texts from Alexandria and Antioch. These bibles were meant for large public services, and so were designed to function as Liturgical Bibles. Codex Vaticanus and Sinaiticus are examples of this first approach.
(5)Between 350-410, a small controversy arose over the verses, resulting in a final, more advanced and evolved Lectionary system, completely separated from the main Gospel copying stream, to minimize further contamination. The early fathers unanimously and firmly attest the authenticity of the verses, and provide a partial and plausible motive for its neglect. At this time (390 A.D.) Jerome also notes the passage is found in many manuscripts both Greek and Latin, and includes it in the new Latin Gospel translation without hesitation.
The two main text-types for the Pericope de Adultera, M5 (the A-text) and M6a (the Dominant B-text) have now become firmly entrenched. There will be some subsequent battles between the texts, as scribes attempt to repair manuscripts suffering from omissions, and the popularity of the Lectionary text in public worship exerts its influence upon the stream of transmission.
(6) Between 450-550 A.D., a few branches of transmission without the verses are perpetuated, while the purer A-text regains its complete dominance through a grassroots (uncontrolled) copying and collating process (here the probability arguments for the Majority Text have the most plausible application). At this time, a few manuscripts such as Codex Bezae are produced, probably in an attempt to preserve one of the earliest and most primitive forms of the B-text (early Lectionary system). The result of this lingering influence from a previous era is the M1 text.
(7) Sometime between the 5th and the 9th century, a reblending of the two main texts occurs. We place the creation of this 'mixed text', the archetype of M7 appropriately early, just after the 5th century, when such an approach would still make sense to those attempting to update and keep alive the Greek text, while late enough to leave some scribes unsure of which text to follow.
(8) Also in this period, the popular and dominant 'semi-final' Lectionary text (M6a), being the one actually in use, and being the more flexible of the two texts, receives some more edits to produce the M6b text. This is very much what happens today with lectionary texts, liturgical handbooks and prayerbooks. The language is updated more often and put in more 'everyday' language, for clarity.
(9) Finally, the M2 text, in again what appears to be a revival or attempt to preserve an earlier form of the Lectionary text, is produced. But it may be equally possible that it was generated from a comparison of the texts available at the time, by mixing and editing. We have no direct trace back to the early Lectionary, nor very many manuscripts, suggesting it is a relatively small eddy-current or dead-end branch of the combined Lectionary-Gospel transmission stream.
(10) M3-M4, a significant group quite obviously derived from the dominant Lectionary tradition, may reflect a final advanced edition, which simply occured too late in the Lectionary process to achieve dominance before the Greek transmission stream was virtually replaced by the Latin in most of the Empire. This groups may then reflect either a 'late' edition, or an early edition that had limited circulation during the time when controversy still swirled around the Pericope de Adultera. These groups include the infamous Family 13 which places the passage in Luke.
When we include M7 in the counting process, support for some minority readings appear to be almost 50-50, and in a few cases possibly even achieving a 'false positive' (Majority) reading. This is why a blind 'majority vote' style of simple manuscript counting is inappropriate.
Just as when in an election we naturally disqualify spoiled ballots and illegal double-votes, or votes from dead people or non-residents, we also have to have some quality control over the manuscript count.
The fact that we know that certain groups of manuscripts are artificial creations made by blending other texts disqualifies them in the voting and counting process. Thus M7, even though it is a relatively large group of manuscripts, must be discounted. Similarly, M3-M4, being obviously produced by the final stages of the Lectionary process, must lose a large amount of credibility, especially in its peculiar readings.
When we exert some sensible control over the 'voting' process, we end up with much more decisive counts for the variants, and also much more decisive and convincing results.