 Last Updated: Oct 21, 2010 |
Base-Texts & The Maj. TextDiscussion: Nazaroo, Blog Comments, (KJVOnly?, 2010) |
|
Last Updated: Oct 21, 2010 |
Base-Texts & The Maj. TextDiscussion: Nazaroo, Blog Comments, (KJVOnly?, 2010) |
Base-Texts and the Majority Text
As a scientist, I find modern TC a ridiculous farce.
For example, what do we do to resolve the other 80-90% of the text? We rely upon the Majority of MSS.
What do we do to resolve the question of Singular Readings of individual MSS? All modern Textual Critics reject them as errors with a high probability.
In other words, for nearly 80-90% of the NT Text, we rely on the Majority of MSS. This appears to be true for ALL textual critics, whatever their personal attitude on how to handle the remainder of readings.
Why is the obvious resort to the Majority of MSS valid for 80-90% of the text valid, but not for the rest?
When we want to establish the remainder of the NT text, it is a fundamental axiom. Why? Because of what it is we are actually seeking. We are seeking what? The text that Christians have been using as authoritative for 2,000 years.
We assume that when the majority of MSS and versions agree to a certain depth (near unanimity) its a valid scientific procedure.
The only question that remains is what to do when a significant handful of ancient MSS dissent from that very same majority. But if the method is valid for 80-90% of the NT text, why isn’t it valid for the remaining 10-20%?
Inconsistency in Method
Modern textual critics want to step in at this point (and the ‘point of crossing’ is very fuzzy and unclear) and use an entirely different set of criteria to determine the text.
The same rule that was perfectly valid and unanimously accepted for 80-90% of the text is now suddenly invalid for the remainder. But no adequate rational explanation is given as to why.
In physics, the same Law of Gravity is used in every single case. We have no “exceptions” in real comprehensive scientific theory: one theory does all, or else it is rejected or severely modified and made to be automatic (scientifically deterministic) in some other way.
This is also true with every other scientific law, method, or theory. The first principle of science is absolute consistency.
In TC by contrast, we have one principle for 80-90% of the NT text, and then an entirely different clumsy set of unscientific “canons” for the rest. This is an absurd situation scientifically, and is wholly rejected by the scientific mind.
Do Textual Critics need one or not?
What is Collating? - comparing Manuscripts (MSS), collecting readings. All textual criticism should probably begin with the collation of MSS. But what is the procedure? What is needed, what tools, skills, what methodology is best?
A Tale of Two Critics
Let us follow two textual critics, Tweedle-dum and Tweedle-dee.
They are confronted by the discovery of a completely new text, of which they have found 5 diverse MS copies from different locals.
They agree that the first thing they must do (before publishing and becoming rich and famous) is to collate these surviving MSS.
Not only do they intend to reap the glory for discovery, but also they want to be known as the experts who restored the lost original.
Immediately there is a problem of method: Tweedle-dum says they need to have a base-text from which to work, noting the variants. He suggests they pick the oldest and/or best MS and use this, adding the variants from the other MSS as footnotes.
Tweedle-dee scoffs at the plan. "Base-text? We don't need no base-text. In any case, what if you choose the wrong MS for a base-text? You'll make us both look like fools!" 1
Tweedle-dum, unintimidated, says: "Look, there's no such thing as the 'wrong' base-text. It will all come out in the footnotes anyway." He humphs off to his own room, taking 2 of the 5 MSS with him, in order to create a 'base-text' from them. 2
Tweedle-dee snickers to himself: "While he's rewriting that long thing out by hand, I'll be able to collate the other 4 in the same amount of time!"
Quickly he sets himself a simple plan: He'll take the MSS in pairs, and jot down differences. Then combine his notes. When buddy gets back, he'll add the variants from MS #5, and voila! All done.
But Tweedle-dum, being a mathematician, is a lazy oaf. He sits down and thinks: "How can I save time and labour? What is the best way to proceed?"
He formulates an even lazier plan than Mr. -dee. "I'll just use MS #1 as a base. I'll note the differences from it in MS #2, then do the same with #3-5. Bingo." He then begins, but the work is so tedious, that he nods off to sleep before quite finishing.
Meanwhile Tweedle-dee is furiously compiling 3 lists: "3-4", "3-5", "4-5", which show the differences between each pair of MSS respectively. He is wondering how to proceed to the next step, when Tweedle-dum saunters in.
Tweedle-dum throws MS #1 & #2 on the table: "I'm done with those. What have you got so far?" Tweedle-dee explains what he's been doing.
Tweedle-dum pauses for a moment to think: "Hmmm.. How can I best use your labours, and you best use mine?"
Tweedle-dee says, "I'll just pair off the other to MSS and make two more lists, then you can help me combine them."
Tweedle-dum stops him: "You're mistaken entirely. If you proceed with your method, you'll have to make SEVEN more lists to cover all pairs. Then I don't know how you'll combine those things. Looks like a lot of work." 3
Tweedle-dee snorts, "You're just angry that I was right. We don't need a base-text, - or the bias and false impression that would cause. You're welcome to use my lists if you want."
Tweedle-dum sits down, brows knotted. "You are essentially correct in that if you pair off all the MSS you will have indeed collated every variant. The problem is, no single list properly collates any individual MS completely. All 4 lists with that MS will have to be consulted to be complete. To completely collate and know any single MS, you will have to consult 4 lists."
Tweedle-dee responds: "Yes, but my collation will be without any bias. And as accurate as yours, only without an inconvenient form, favouring an arbitrary MS."
Tweedle-dum picks up MS #3, and continues. "Very well. I can't see how using your data can speed up my method in any way. If I use your 3-4 and 3-5 lists, I can certainly have a complete collation of 4 and 5, once I also collate 3 to my base-text, but that saves no time, and invites errors. I can just as easily collate 3, 4, 5 in turn in the same or faster time."
Tweedle-dee ponders; "Why faster?"
Tweedle-dum says, "Compiling my apparatus on the fly, I automatically combine readings supported by more than one MS in the same note. All the readings accumulate naturally and easily. By the time I'm done collating these three MSS, I'll be ready to publish my text. As I collate, I am making other notes and observations, which I can add to the Introduction."
Tweedle-dee looks forlornly over at Tweedle-dum's wide-margin base-text, with apparatus. "Maybe it would be better if I just cut my losses, and help you collate these three MSS. After we are done, we can remove all singular readings, and simplify the apparatus further."
Tweedle-dum smiles at his friend. "Agreed. I think that will be the best use of our time.." Secretly he snickers, knowing he has only had to collate 2 or 3 MSS, and they will publish way ahead of other less astute textual critics.
1. It is not impossible to collate manuscripts without a base-text, but it will be observed that there is no reason not to use one, since the work of collation is cut down by a massive amount in using one. There is no more efficient way of collating MSS known than the one illustrated.
2. Tweedle-dum is correct. There is nothing to fear in using any base-text, since it is essentially just an efficient repository of variant readings. If the collation is complete and thorough, any starting base-text will perform the key function. The question of placing what is believed to be the original readings in the main text, while recording secondary readings in the margin/footnotes is really just mechanical typesetting task, once readings have been evaluated.
3. Tweedle-dum is again right. It may not seem inconvenient to skip a base-text with only 5 MSS to compare, but it quickly gets out of hand with more. The number of possible MS Pairs is given by the formula:
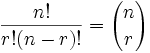
...where n is the number of MSS, and r is the group-size (in this case 2, for a pair). This is the number of times one will have to compare two MSS all the way through, letter by letter. To get an idea of the problem, consider 10 MSS: Collating using a base-text means making 9 full passes through each (remaining) MS once. Without a base-text, complete collation requires: Combinations for 10 MSS = 45 passes! This is five times as much collating, even without subsequent necessary processing of the pair-lists formed.
Does it matter?
The Wrong Base-Text
As things shape up in the collating, Tweedle-dee notices that a large number of MSS diverge from the Base-Text quite often, and in frequently similar pair-offs.
“Look at this: I was right, you chose the wrong base-text!”
Tweedle-dum studies the apparatus. “You are right. The data can be simplified, and more than that, we still did the right thing. For having to switch base-texts is next to nothing, compared to the work you proposed of collating MS pairs 10 times, and then trying to come up with a scheme to combine your incomplete lists.” 4
Tweedle-dee and Tweedle-dum simply copy out MS#4, which looks to be the real “Base-Text”. Then, the apparatus becomes greatly simplified, as instead of noting where 4 MSS diverge from MS #1 (often), they can simply note the singular reading of MS #1 in the margin.
Tweedle-dum speaks up, as many remaining variants simply re-appear as singular readings. “We can simplify this apparatus immensely, making it easier and more useful, by eliminating all the singular readings.”
Tweedle-dee says, “Yes. We’ll make a note in the introduction, that singular readings have been ignored, except any unusual and significant cases.”
Tweedle-dum notes, “Even with the wrong initial base-text, we have saved many many hours of collating, and have an efficient, largely accurate and useful expression of the variants, which now emphasizes the best text!”
Tweedle-dee says, “Yes, Tweedle-dum. Your mathematical aptitude and sheer laziness has paid off bigtime.”
Tweedle-dum mumbles, “I think that’s a compliment. Thanks.”
4. However, it is not automatic or always simpler to switch base-texts. If you already have a good base-text, not differing constantly from the majority of MSS or witnesses to be compared, then choosing a worse text will actually bloat the apparatus and involve much more work to manually typeset. But in general, if the most common and frequent readings are in the text, the minority variants will be most efficiently displayed in the margin, in a very concise manner, without having the user of the apparatus constantly misled.
Furthermore, one should note that the most efficient and concise way of displaying the data does not automatically prove the "Majority Text" theory, i.e., that that Majority text is the original, or always the best choice of variants. It will nonetheless remain the most concise and easy-to-use form in which the variants can be conveniently tabulated.
